
You can remember when you struggled to get the information you wanted from your AI tool. You may want to pull together a report with images or analyze a video to extract insights into customer behavior. Either way, you likely found it frustrating that your AI could only handle one data type at a time. Multimodal LLMs, or multimodal large language models, are designed to overcome this limitation. They are a new type of AI model that can analyze and generate multiple forms of data, including text, images, audio, and video. This article will provide valuable insights to help you reach your goals, like understanding what multimodal LLMs are, their key components, and how they can be applied across different models and use cases.
Lamatic's generative AI tech stack features multimodal LLM that can help you achieve your goals. Our solution can help you better understand multimodal LLMs, their components, and how they can be applied across various use cases so you can easily leverage them to improve your business operations.
What is a Multimodal LLM?

A multimodal language model (LLM) is an advanced version of artificial intelligence capable of generating and processing multiple modalities or forms of data. Unlike traditional language models that primarily focus on textual data, LLMs can understand and generate content from diverse sources such as text, images, audio, and even video. A multimodal LLM is an AI system that can perceive and create content that involves more than just text. It can understand and generate information that combines text with visual elements like images or diagrams, audio recordings, or even videos.
What is Multimodal Learning?
Multimodal learning refers to training machine learning models on data that combines multiple modalities or sources of information. Instead of relying on a single input modality, these models are designed to simultaneously learn from and integrate information from various modalities.
Why Does Multimodal Learning Matter?
Imagine having a friend who can understand not just your words but can also understand images, audio and videos which you send to him and it will make the conversation more fun. The main problem with older singular model LLMs was that they were not able to understand more than one modality at a time and sometimes it becomes hard to properly explain your problem or output for both LLM and you too. Here is why multimodal LLMs are important:
- Filling the Gap Between Text and Reality: Text alone can be hard to explain or understand sometimes, and this is where multimodal LLMs make it easy. For example, suppose you want to do one project and want some suggestions on reviewing its architecture. You can easily provide an image of a flow diagram of architecture, and it can provide reviews on it and create updated architecture simultaneously.
- More Creativity: Multimodal LLMs have increased the creative capability of normal LLMs by providing multiple modalities simultaneously. They can generate videos based on text or create a story from an image.
- Improving Human-Computer Interaction: Multimodal LLMs have increased the quality of conversation by making it more realistic with multiple modalities. It's just the same as texting your friend.
What’s the Difference Between Unimodal and Multimodal Learning?
In unimodal learning, every model is trained on a dataset of data with a singular modality. On the other hand, multimodal models are trained on multiple modality or forms of data, which makes them more precise and creative. Unimodal learning is very useful in classification tasks such as image recognition, which can classify images, detect objects inside an image, or classify different tasks. In complex problems, such as disease prediction, more than the image is required to predict the disease type accurately. In such cases, multimodal learning helps us increase our understanding of disease.
What are the Different Data Modalities?
Different data modes include text, image, audio, and tabular data. One data mode can be represented or approximated in another data mode. For example:
- Text: This is one of LLMs' most common modes or forms of data. They can process and understand text, which allows them to analyze data, generate text descriptions, translate languages, and answer your questions in an informative way.
- Images: These can be converted into vector embeddings or any other format so that LLMs can understand them and find objects in an image, generate images, or find similar images for a given image.
- Audio: Files can be processed by analyzing audio data, recognizing speech patterns, understanding the sentiment behind audio, or even converting the audio into text or vice versa.
- Video: By combining image and audio processing, multimodal LLMs can analyze videos by breaking down a video into frames and audio tracks, analyzing the content of each frame, finding objects in the video, or generating summaries of video content
Related Reading
- LLM Security Risks
- What is an LLM Agent
- AI in Retail
- LLM Deployment
- How to Run LLM Locally
- How to Use LLM
- LLM Model Comparison
- AI-Powered Personalization
- How to Train Your Own LLM
Components of a Multimodal LLM

Modality Encoders: The Key to Multimodal LLMs
You must first learn about modality encoders to understand how multimodal LLMs work. These encoders, or tokenizers, convert data from different modalities into a format that LLMs can understand. Just as unimodal LLMs use encoders to process text data, multimodal LLMs require different encoders for each input data type, such as:
- Images
- Audio
- Video
Modality encoders are crucial to the performance of multimodal LLMs. Each encoder extracts specific information from its corresponding input data. For example, the text encoder might extract semantic representations from text, while the image encoder extracts visual features from images.
Input Projector: Merging Different Modality Inputs
Once we have all the encoded data from individual modalities, we must combine it in a single format. The input projector combines the encoded representations of data in a unified format.
This is typically done by concatenating or projecting the modality-specific representations (output of modality encoders) into a shared embedding space. This allows the LLM to consider all the information together and work with different modalities of data simultaneously. The LLM backbone then uses this representation.
LLM Backbone: The Core Component of Multimodal LLMs
The LLM backbone is the core component of multimodal LLMs. It is a large language model trained on a huge amount of data, similar to the models used in text-only tasks.
It is responsible for getting data representation from the input projector and generating outputs like text descriptions, summaries, or other creative content. These LLMs are trained to work with data from different modalities like images or audio through the combined input representation.
Output Projector: Exporting Multimodal LLM Output
Once the LLM backbone completes the generation task, we must convert the encoded data back into the desired format or modality if needed. The output projector takes the LLM's output and converts it back to the desired format for the target task.
For example, if the task is to caption an image, the output projector will convert the LLM’s output into a sequence of words describing the image. Output projectors can also output in different modalities, like modality encoders.
Modality Generators: Creating New Data for Multimodal Tasks
For some multimodal LLMs, you might need a modality generator to generate the output data in different modalities based on your target task. For example, if the task is to generate audio, then a modality generator will take the output from the LLM backbone and generate corresponding audio.
Modality generators can be implemented using various techniques, such as:
- Generative adversarial networks (GANs)
- Variational autoencoders (VAEs)
- Diffusion models
Depending on your target modality or task.
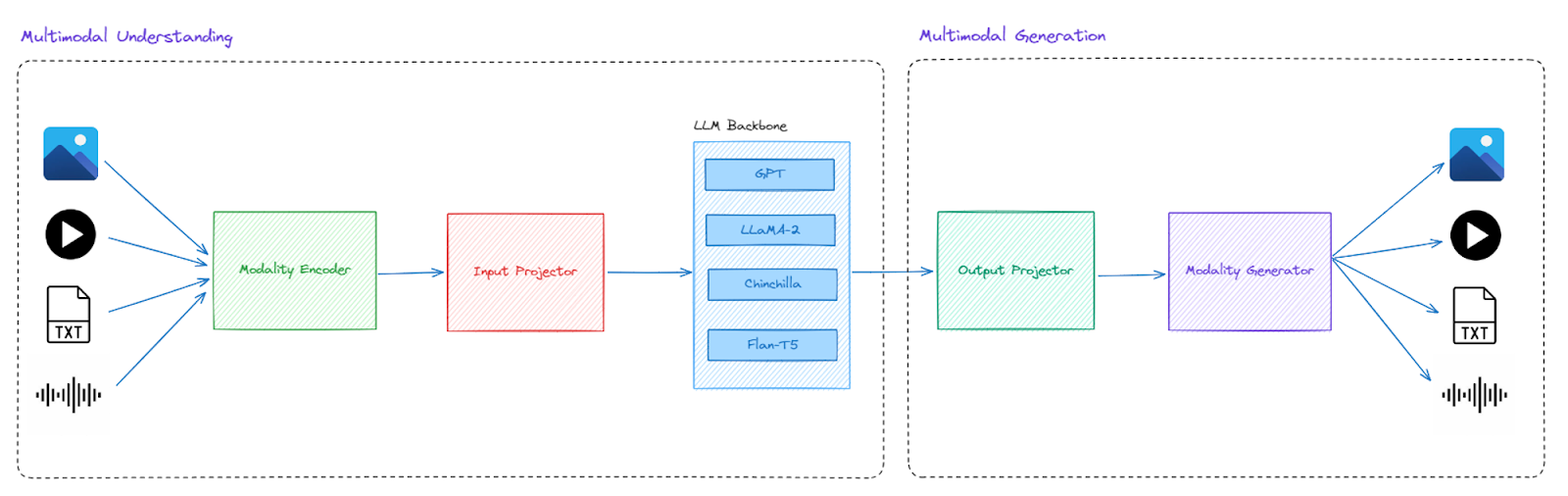
How Do Multimodal Language Models Work?
Multimodal language models integrate and process information from multiple data modalities, such as text, images, audio, and video, to understand and generate comprehensive responses.
Here’s a breakdown of how they work:
Data Preprocessing
Each type of data is preprocessed to make it suitable for the model. This involves tokenization for text, feature extraction for images, and audio signal processing for audio. Preprocessing ensures that the data is in a format the model can understand.
Feature Extraction
MLLMs use specialized neural networks to extract relevant features from each modality. For example:
- Text: Natural language processing (NLP) techniques extract linguistic features like syntax and semantics.
- Images: Convolutional neural networks (CNNs) detect visual features like shapes, colors, and objects.
- Audio: Recurrent neural networks (RNNs) or convolutional neural networks (CNNs) analyze sound patterns and frequencies.
- Video: Combines image and audio processing techniques to understand visual and auditory components over time.
Modality Encoders
Separate encoders process each input data type, transforming it into a unified feature space. These encoders map different data modalities into a common representation, enabling the model to work effectively with heterogeneous data.
Cross-Modal Attention
Cross-modal attention mechanisms allow the model to focus on relevant parts of the data across different modalities. This process helps the model align and integrate information, ensuring the response is coherent and contextually appropriate. For example, while generating an image description, the model can focus on the visual content and any accompanying text to produce a more accurate description.
Joint Representation
The model creates a joint representation by combining the processed features from each modality. This representation captures the relationships and dependencies between the data types, allowing the model to generate integrated and contextually rich outputs.
Multimodal Fusion
Various fusion techniques combine features from different modalities. Early fusion integrates the features at the initial processing stages, while late fusion combines them after each modality has been processed independently. Hybrid approaches can also be used to balance the advantages of both methods.
Training
MLLMs are trained using large datasets that include paired examples of different modalities (e.g., images with captions and videos with audio descriptions). The training process involves optimizing the model to minimize errors in predicting outputs based on the integrated multimodal input. Techniques such as backpropagation and gradient descent adjust the model's parameters.
Inference
During inference, the trained model processes new multimodal inputs using the same steps:
- Preprocessing
- Feature extraction
- Encoding
- Cross-modal attention
- Multimodal fusion
The model then generates responses or predictions based on the joint representation of the input data.
Applications of Multimodal LLMs
Let’s take a look at some of the real-world applications and use cases of multimodal LLMs
Revolutionizing Search Engines
Most search engines only allow text searches, and you can do image searches using Google image search. Imagine searching for:
- Images
- Audio
- Videos
Using a single search engine and getting results in different modalities. Multimodal LLMs can revolutionize search engines' capability in this area.
Boosting E-commerce Experiences
Imagine trying on clothes virtually without leaving your home! Multimodal LLMs could analyze your body measurements and a chosen garment (image or video) to create a realistic simulation of how it would look on you. They can also provide suggestions on clothes that match your style.
Medical Diagnosis and Treatment
Multimodal LLMs could analyze medical images (X-rays, MRIs) alongside patient medical history and even speech patterns during consultations to assist doctors in diagnosis. They could also generate reports summarizing findings and suggest potential treatment plans based on the combined information.
Empowering Education
Learning can be more engaging and interactive with multimodal LLMs after they are supported by multiple modalities. Analyzing images or videos of customer issues to provide more detailed solutions or feedback on tickets will also increase the ability of customer service chatbots to work with human support tickets.
Related Reading
- How to Fine Tune LLM
- How to Build Your Own LLM
- LLM Function Calling
- LLM Prompting
- What LLM Does Copilot Use
- LLM Evaluation Metrics
- LLM Use Cases
- LLM Sentiment Analysis
- LLM Evaluation Framework
- LLM Benchmarks
- Best LLM for Coding
13 Popular Multimodal Large Language Models

1. Flamingo: A Multimodal Powerhouse
Flamingo is a multimodal LLM that was presented in 2022. Here’s how the vision and language components work:
- The vision encoder converts images or videos into embeddings (lists of numbers). These embeddings vary in size depending on the dimensions of the input images, or the lengths of the input videos, so another component called the Perceiver Resampler converts these embeddings to a common fixed length.
- The language model takes in text and the fixed-length vision embeddings from the Percever Resampler.
- Given the current text, the vision embeddings are used in multiple “cross-attention” blocks, which learn to weigh the importance of different parts of the vision embedding.
Training occurs in three steps:
- Vision Encoder: is pre-trained using CLIP (see the next section for an explanation). CLIP trains both a vision and text encoder, so the text encoder from this step is discarded.
- Language Model: is a Chinchilla model pre-trained on next-token prediction, i.e., predicting the next group of characters given a series of previous characters. This is how most LLMs like GPT-4 are trained. You might hear this type of model referred to as “autoregressive,” which means the model predicts future values based on past values.
- Untrained Cross-Attention Blocks: Are inserted into the language model, and an untrained Perceiver Resampler is inserted between the vision encoder and the language model.
This is the complete Flamingo model, but the cross-attention blocks and the Perceiver Resampler must be trained. The entire Flamingo model is used to compute tokens in the next-token prediction task, but the inputs now contain images interleaved with text. The weights of the vision encoder and the language model are frozen. Only the Perceiver Resampler and cross-attention blocks are updated and trained. Flamingo can perform vision-language tasks, including answering questions about images in a conversational format.
What is CLIP?
As mentioned in the previous section, Flamingo uses CLIP in its pretraining stage. CLIP is not a multimodal LLM. It is a training methodology that produces separate vision and text models with powerful downstream capabilities. CLIP stands for Contrastive Language-Image Pre-training, and it is conceptually very simple. The model architecture consists of an image encoder and a text encoder.
- The image encoder converts images to embeddings (lists of numbers).
- The text encoder converts text to embeddings.
The two encoders are trained on batches of image-text pairs in which the text describes the image. The encoders are trained such that: For each image-text pair, the image and text embeddings are “close” to each other. The image and text embeddings are far from each other for all non-matching image-text pairs.
Note: There are many ways to measure the distance between two embeddings. Some common ways are Euclidean distance and cosine similarity. CLIP uses the latter. CLIP learns a joint image-text embedding space at a high level, meaning the similarity between images and text can be directly computed. Training models with this goal make them useful, including in multimodal LLMs.
2. BLIP-2: Sounding Good
BLIP-2 is a multimodal LLM that was released in early 2023. Like Flamingo, it contains a pre-trained image encoder and LLM. However, unlike Flamingo, the image encoder and LLM are left untouched (after pretraining). To connect the image encoder to the LLM, BLIP-2 uses a “Q-Former,” which consists of two components:
- The visual component receives a set of learnable embeddings and the output of the frozen image encoder.
- As done in Flamingo, the image embeddings are fed into cross-attention layers.
Training BLIP-2 occurs in two stages:
Stage 1
The two components of the Q-Former are trained on three objectives, which originate from the BLIP-1 paper:
- Image-text contrastive learning (similar to CLIP but has some subtle differences).
- Image-grounded text generation (generating captions of images).
- Image-text matching (a binary classification task where the model has to answer 1 for each image-text pair to indicate a match and 0 otherwise).
Stage 2
The full model is constructed by inserting a projection layer between the Q-Former and the LLM. This projection layer transforms the Q-Former’s embeddings into LLM-compatible lengths. The full model is then tasked with describing input images. During this stage, the image encoder and LLM remain frozen, and only the Q-Former and projection layers are trained. The paper’s experiments use a CLIP-pretrained image encoder and either OPT or Flan-T5 for the LLM. The experiments show that BLIP-2 can outperform Flamingo on various visual question-answering tasks but with a fraction of the trainable parameters. This makes training easier and more cost-effective.
5. LLaVA: A Simple Approach
LLaVA is a multimodal LLM that was released in 2023. The architecture is quite simple: The vision encoder is pre-trained using CLIP. The LLM is a pre-trained Vicuna model. The vision encoder is connected to the LLM by a single projection layer. Note the simplicity of the component between the vision encoder and the LLM, in contrast with the Q-Former in BLIP-2, and the Perceiver Resampler and cross-attention layers in Flamingo.
There are two training stages:
Stage 1
The training objective is image captioning. Only the projection layer is trained since the vision encoder and LLM are frozen.
Stage 2
The LLM and projection layer are finetuned to a partially synthetic instruction-following dataset. It’s partially synthetic because it’s generated with the help of GPT-4.
LLaVA Architecture
The authors evaluate LLaVA as follows:
- They use GPT-4 to evaluate the quality of LLaVA’s responses on a partially synthetic dataset. LLaVA scores 85% relative to GPT-4.
- They use standard evaluation metrics on a visual question-answering dataset called ScienceQA. A fine-tuned LLaVA outperforms GPT-4.
LLaVA illustrates that a simple architecture can achieve excellent results when trained on partially synthetic data.
6. DALL-E: Image Generation from Text Prompts
Developed by OpenAI Description, DALL-E generates images from textual descriptions, showcasing the ability to create visual content based on detailed text prompts. It demonstrates the integration of language and vision capabilities.
7. Florence: Microsoft's Foundation Model for Vision Tasks
Florence is a foundation model designed for computer vision tasks. It integrates textual descriptions with visual data to perform various tasks, including:
- Image captioning
- Visual question answering
8. ALIGN: Understanding Text from Images
ALIGN is a model trained to understand and generate text from images by aligning visual and linguistic representations. It can perform cross-modal retrieval and zero-shot image classification.
9. ViLBERT: Extending BERT to Visual and Textual Data
ViLBERT extends the BERT architecture to handle visual and textual data simultaneously. It can be used for tasks such as visual question answering and visual commonsense reasoning.
10. LXMERT: Learning Cross-Modality with Transformers
LXMERT is a model that encodes visual and textual data using separate transformers and then merges the information for tasks like visual question answering and image captioning.
11. Gemini: Google's Multimodal LLM
In 2023, Google announced its multimodal LLM called Gemini, which can work with different modalities like:
- Images
- Text
- Audio
- Video
Gemini can also do multi-modality-based question answering, which means you can ask questions in the form of more than one modality simultaneously. Like GPT-4, Gemini is also limited to generating image and text responses, but both can take multiple modalities as input.
12. UNITER: Universal Representation Learning
UNITER learns joint representations of images and text, achieving state-of-the-art results on several vision-and-language tasks, such as visual question answering and image-text retrieval.
13. ERNIE-ViL: Integrating Knowledge for Visual-Linguistic Tasks
ERNIE-ViL enhances visual-linguistic pre-training by integrating structured knowledge and improving performance on tasks such as visual question answering and image captioning.
Challenges and Considerations in Deploying Multimodal LLMs
Multimodal LLMs are computational powerhouses. They analyze data across different modalities, such as text, images, and audio, predicting the next output based on patterns learned from training data.
Multimodal LLMs can be massive, with some of the largest models containing over a trillion parameters. Training and deploying these models require substantial computational resources, such as hardware and electricity, making them expensive and potentially limiting their accessibility.
The Biases of Multimodal LLMs
Multimodal LLMs inherit biases in their training data, which can lead to unfair outcomes. For example, suppose a model learns from a dataset of pictures showing people of different races and genders working in specific occupations. In that case, it may associate certain jobs with particular demographic groups.
When given a prompt about a job, the model’s response may reflect these biases, perpetuating stereotypes. Ensuring diverse and representative training data is crucial to mitigating these risks.
The Complexity of Multimodal LLMs
Like other AI models, multimodal LLMs are complex and challenging to understand. A typical LLM can have billions of parameters, and multimodal LLMs can be even larger.
The complexity of these models can make it difficult to understand how they arrive at their decisions, raising concerns about transparency and trust. For organizations looking to implement these models, such challenges can hinder their adoption and use, as stakeholders may be wary of relying on systems that act like a black box.
The Ethical and Environmental Considerations of Multimodal LLMs
The development and use of multimodal LLMs must be guided by ethical considerations, including the potential environmental impact of their computational demands. For example, research shows that training a single large AI model can emit the same amount of carbon as five cars over their lifetimes. As multimodal LLMs become more common, organizations must consider and mitigate their environmental impact, such as purchasing carbon offsets to balance emissions.
Related Reading
- LLM Quantization
- LLM Distillation
- LLM vs SLM
- Best LLM for Data Analysis
- Rag vs LLM
- Foundation Model vs LLM
- ML vs LLM
- LLM vs Generative AI
- LLM vs NLP
Start Building GenAI Apps for Free Today with Our Managed Generative AI Tech Stack
Lamatic offers a managed Generative AI tech stack that helps teams implement GenAI solutions without accruing tech debt. Our solution provides:
- Managed GenAI middleware
- A custom GenAI API (GraphQL)
- Low code agent builder
- Automated GenAI workflow (CI/CD)
- GenOps (DevOps for GenAI)
- Edge deployment via Cloudflare Workers
- Integrated vector database (Weaviate)
Start building GenAI apps for free today with our managed generative AI tech stack.





