
As powerful as cloud-based LLMs are, they come with privacy and cost concerns that can affect the performance of your applications. What if you could sidestep these issues entirely? By running LLMs locally, you can dramatically reduce latency, ensuring faster response times and bolstering your operations' privacy. In this post, we’ll explore how to run LLM locally and offer insights and tips to help you integrate and deploy local multimodal LLM within your product to enhance performance, privacy, and cost efficiency without relying on cloud-based solutions.
One way to accelerate your journey is by using Lamatic’s generative AI tech stack. This solution will help you confidently integrate and deploy local LLMs within your product to enhance performance, privacy, and cost-efficiency without relying on cloud-based solutions.
What Is a Local LLM & Why Use Local LLMs?

Local large language models are machine learning models that run directly on a user’s hardware rather than relying on cloud-based services. The advantages of local LLMs include:
- Data privacy
- Reduced latency
- Independence from Internet connectivity
For example, local LLMs can securely analyze documents without sending sensitive data to the cloud.
Local LLMs for Privacy and Cost-Efficiency
LLMs can also power offline AI applications and enable enterprise-level customizations. Cloud-based LLMs have their advantages, but there are scenarios where a local LLM is more beneficial. These include applications that require data privacy, such as healthcare and use cases that involve high-volume, long-term operations that can lead to significant cloud costs.
Can I Run an LLM Locally?
You might wonder, "Can I actually run an LLM on my local workstation?" The good news is that you can likely do so if you have a relatively modern laptop or desktop! However, some hardware considerations can significantly impact the speed of prompt answering and overall performance.
Hardware Requirements
While not strictly necessary, having a PC or laptop with a dedicated graphics card is highly recommended. This will significantly improve the performance of LLMs, as they can leverage the GPU for faster computations. LLMs might run quite slowly without a dedicated GPU, making them impractical for real-world use.
Hardware Considerations
LLMs can be quite resource-intensive, so having enough RAM and storage space to accommodate them is essential. The exact requirements will vary depending on your specific LLM, but having at least 16GB of RAM and a decent amount of free disk space is a good starting point.
Software Requirements
Besides the hardware, you also need the right software to effectively run and manage LLMs locally. This software generally falls into three categories:
1. Servers
These run and manage LLMs in the background, handling tasks like loading models, processing requests, and generating responses. They provide the essential infrastructure for your LLMs. Some examples are Ollama and Lalamafile.
2. User Interfaces
These provide a visual way to interact with your LLMs. They allow you to input prompts, view generated text, and customize the model's behavior. User interfaces make it easier to experiment with LLMs. Some examples are OpenWebUI and LobeChat.
3. Full-Stack Solutions
These are all-in-one tools that combine the server and the user interface components. They handle everything from model management to processing and provide a built-in visual interface for interacting with the LLMs. They are particularly suitable for users who prefer a simplified setup. Some examples are GPT4All and Jan.
Open Source LLMs
You need the LLMs themselves. These large language models will process your prompts and generate text. Many different LLMs are available, each with its own strengths and weaknesses. Some are better at generating creative text formats, while others are suited for writing code. Where can you download the LLMs from? One popular source for open-source LLMs is Hugging Face. They have an extensive repository of free models you can download and use. Here are some of the most popular LLMs to get started with:
- Llama 3: The latest iteration in Meta AI's Llama series, known for its strong performance across various natural language processing tasks. It's a versatile model suitable for a wide range of applications.
- Mistral 7b: A relatively lightweight and efficient model that performs well even on consumer-grade hardware. It's a good option for those who want to experiment with LLMs without access to powerful servers.
- LLaVA: An innovative large multimodal model that excels at understanding both images and text, making it ideal for tasks like:
- Image captioning
- Visual question answering
- Building interactive multimodal dialogue systems
When choosing an LLM, consider the task you want it to perform, the hardware requirements, and the model size. Some LLMs can be large, so you'll need enough storage space to accommodate them.
Why Use Local LLMs?
Data Privacy and Confidentiality
Running LLMs locally ensures that sensitive data never leaves your machine. This is crucial in healthcare and legal services industries, where client data must remain confidential. For instance, medical professionals handling patient data can avoid sending protected health information to cloud services, staying compliant with privacy regulations like HIPAA.
Cost Savings
Using cloud-based AI models often incurs substantial costs. Subscription fees, data storage expenses, and usage charges can add up quickly. With local models, there are no ongoing fees once you’ve downloaded the necessary files, making it a cost-effective solution, particularly for businesses running large-scale AI tasks.
Customizability and Control
Local LLMs offer greater flexibility for customization. You can fine-tune models to fit specific domains or tasks better, improving their accuracy and relevance. By running models locally, you also control when updates are applied, avoiding sudden changes that might disrupt workflows.
Offline Availability
Working in remote areas without internet access? Local LLMs don’t require constant connectivity, allowing users to run queries and perform tasks anywhere. This is especially useful for working remotely with researchers, scientists, and outdoor professionals.
Reproducibility
Cloud-based models are subject to changes in their underlying algorithms, potentially leading to inconsistent outputs over time. Running a model locally ensures that the results remain consistent, a critical aspect for researchers or anyone conducting long-term studies.
What Can These Tools Do?
Before using local LLM tools, it's important to understand what they can and aren't.
Downloading and Running Pre-Trained Models
These tools allow you to download and interact with pre-trained models (e.g., Llama, GPT-2) from platforms like Hugging Face. Pre-trained models have already undergone intense training on large datasets (handled by AI research labs or companies).
Fine-Tuning
Some tools let you fine-tune these pre-trained models on smaller datasets to optimize them for specific tasks or industries. This is lighter than training from scratch but requires technical knowledge and computing resources.
Training
Training a model from scratch (i.e., starting with an untrained neural network and teaching it language from raw data) is beyond the scope of these tools. This process requires advanced machine learning expertise and powerful hardware beyond what consumer laptops can handle.
Models Have Their System Requirements
Each model will have its own system requirements. While smaller models like GPT-2 can run on consumer-grade hardware, larger models such as Llama-13B may require much more RAM and processing power (e.g., GPUs) to run efficiently. Check the requirements for the specific model you wish to use and ensure your hardware can handle it.
Related Reading
- LLM Security Risks
- What is an LLM Agent
- AI in Retail
- LLM Deployment
- How to Use LLM
- LLM Model Comparison
- AI-Powered Personalization
- How to Train Your Own LLM
How to Run LLM Locally

Running a large language model locally can help you avoid cloud-hosted services' costs and data privacy concerns. It can also give you more control over the performance and output of the model. The general process of running an LLM locally involves installing the necessary software, downloading an LLM, and then running prompts to test and interact with the model.
This process can vary significantly depending on the model, its dependencies, and your hardware.
How to Install a Local LLM
For this guide, we will use LM Studio to show you how to install an LLM locally. It's one of the best options for the job (though there are quite a few others). It's free to use, and you can set it up on:
- Windows
- MacOS
- Linux systems
System Requirements and Installation
The first step is to download LM Studio from the official website, taking note of the minimum system requirements: LLM operation is demanding. Hence, you need a powerful computer to do this. Windows or Linux PCs supporting AVX2 (typically on newer machines) and Apple Silicon Macs with macOS 13.6 or newer will work; at least 16GB of RAM is recommended. On PCs, at least 6GB of VRAM is recommended too. When you've got the software up and running, you need to find an LLM to download and use; you won’t be able to do much without one. Part of the appeal of LM Studio is that it recommends "new and noteworthy" LLMs on the front screen of the application, so if you've got no idea what LLM you want, you can pick one from here.
What to Expect When Running an LLM
LLMs vary by size, complexity, data sources, purpose, and speed. There's no right or wrong answer for which one to use, but there's plenty of information on Reddit and Hugging Face if you want to research. LLMs can run to several gigabytes in size, so you can do some background reading while you wait for one to download.
Finding and Downloading LLMs
If you see an LLM you like on the front screen, just click Download. Otherwise, you can run a search or paste a URL in the box at the top. You'll be able to see the size of each LLM to estimate download times and the date when it was last updated. It's also possible to filter the results to see the models that have been downloaded the most.
Managing Your LLMs
You can install as many LLMs as you like (as long as you have the space), but if there's at least one on your system, they'll appear in the My Models panel. (Click the folder icon on the left to get to it.) From here, you can see information about each model that you've installed, check for updates, and remove models.
How to Interact with a Local LLM
To start doing some prompting, open up the AI Chat panel via the speech bubble icon on the left. Choose the model you want to use at the top, then type your prompt into the user message box at the bottom and hit Enter. Your output will be familiar if you've used an LLM such as ChatGPT. On the right-hand side, you can control various settings related to the LLM, including how longer responses are handled, and how much of the processing work is offloaded to your system's GPU. There's also a box for a "pre-prompt:" You can tell the LLM to always respond in a particular tone or language style, for example.
Key Features and Options
Click the New Chat button on the left to start a fresh conversation. Your previous chats are logged in case you need to get back to them. Whenever a particular answer has finished generating, you can:
- Take a screenshot
- Copy the text
- Regenerate a different answer from the same prompt
Related Reading
- How to Fine Tune LLM
- How to Build Your Own LLM
- LLM Function Calling
- LLM Prompting
- What LLM Does Copilot Use
- LLM Evaluation Metrics
- LLM Use Cases
- LLM Sentiment Analysis
- LLM Evaluation Framework
- LLM Benchmarks
- Best LLM for Coding
10+ Best LLM Tools To Run Models Locally
1. LM Studio: Your Local LLM Powerhouse
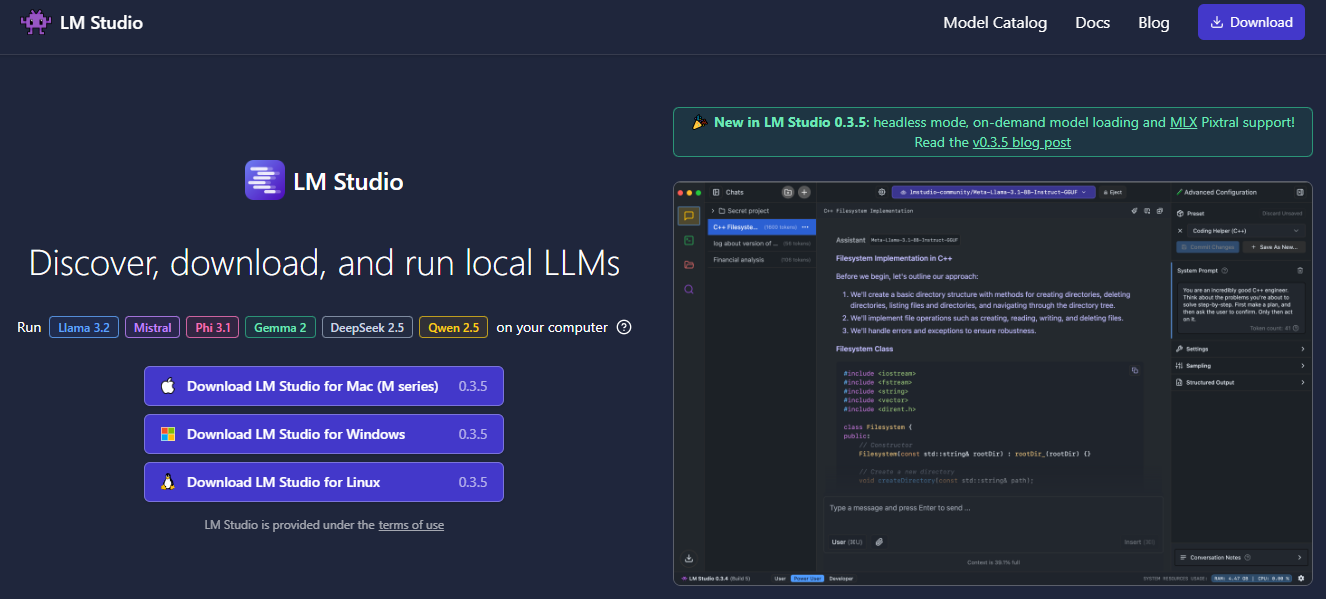
LM Studio is a tool designed to run any model file with the format gguf. It supports GGUF files from model providers such as:
- Llama 3.1
- Phi 3
- Mistral
- Gemma
To use LM Studio, visit the link above and download the app for your machine. Once you launch LM Studio, the homepage will present the top LLMs to download and test. There is also a search bar to filter and download specific models from different AI providers.
Available LM Studio Models
Searching for a model from a specific company presents several models, ranging from small to large quantization. Depending on your machine, LM Studio uses a compatibility guess to highlight the model that will work on that machine or platform.
Key Features of LM Studio
LM Studio provides functionalities and features similar to ChatGPT. It has several functions. The following highlights the key features of LM Studio:
- Model Parameters Customization: This allows you to adjust the:
- Temperature
- Maximum tokens
- Frequency penalty
- And more
- Chat History: Allows you to save prompts for later use.
- Parameters and UI Hinting: You can hover over the info buttons to look at model parameters and terms.
- Cross-Platform: LM Studio is available on Linux, Mac, and Windows operating systems.
- Machine Specification Check: LM studio checks computer specifications like GPU and memory and reports on compatible models. This prevents downloading a model that might not work on a specific machine.
- AI Chat and Playground: Chat with a large language model in a multi-turn chat format and experiment with multiple LLMs by loading them concurrently.
- Local Inference Server for Developers: Allows developers to set up a local HTTP server similar to OpenAI’s API.
- LM Studio Local Inference Server: The local server provides sample Curl and Python client requests. This feature helps to build an AI application using LM Studio to access a particular LLM.
Benefits of Using LM Studio
This tool is free for personal use and allows developers to run LLMs through an in-app chat UI and playground. It provides a gorgeous and easy-to-use interface with filters and supports connecting to OpenAI's Python library without needing an API key.
Companies and businesses can use LM Studio on request. Nevertheless, it requires an M1/M2/M3 Mac or higher or a Windows PC with a processor that supports AVX2. Intel and AMD users are limited to using the Vulkan inference engine in v0.2.31.
2. Jan: Your Open Source Local LLM Assistant
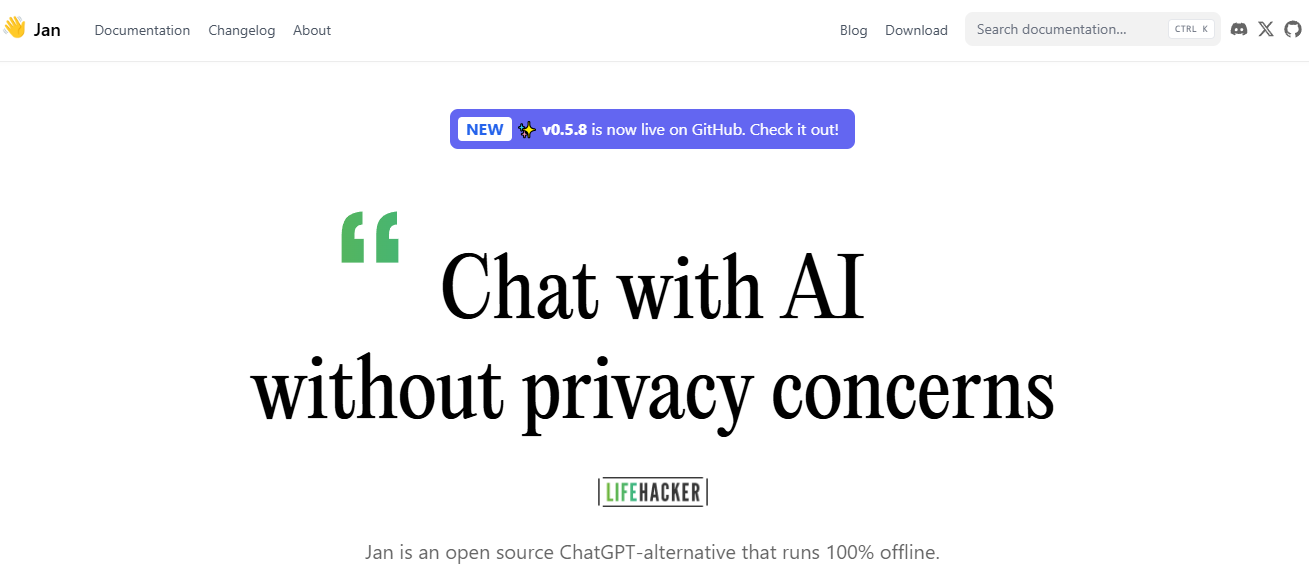
Think of Jan as an open-source version of ChatGPT designed to operate offline. It is built by a community of users with a user-owned philosophy. Jan allows you to run popular models like Mistral or Llama on your device without connecting it to the internet. You can also access remote APIs like OpenAI and Groq with Jan.
Key Features of Jan
Jan is an electron app with features similar to LM Studio. It makes AI open and accessible by turning consumer machines into AI computers. Since it is an open-source project, developers can contribute to it and extend its functionalities. The following breaks down Jan's major features:
- Local: You can run your preferred AI models on devices without connecting them to the internet.
- Ready to Use Models: After downloading Jan, you get a set of already installed models. You can also search for specific models.
- Model Import: It supports importing models from sources like Hugging Face.
- Free, Cross-Platform, and Open Source: Jan is 100% free and open-source and works on Mac, Windows, and Linux.
- Customize Inference Parameters: Adjust model parameters such as:
- Maximum token
- Temperature
- Stream
- Frequency penalty and more
All preferences, model usage, and settings stay locally on your computer. - Extensions: Jan supports extensions like TensortRT and Inference Nitro for customizing and enhancing your AI models.
Benefits of Using Jan
Jan provides a clean and simple interface to interact with LLMs, keeping all your data and
processing information locally. It has over seventy large language models already installed for you to use.
The availability of these ready-to-use models makes it easy to connect and interact with remote APIs like OpenAI and Mistral. Jan also has:
- Great GitHub
- Discord
- Hugging Face communities to follow and ask for help
Like all the LLM tools, the models work faster on Apple Silicon Macs than on Intel ones.
3. Llamafile: The Local LLM Game Changer
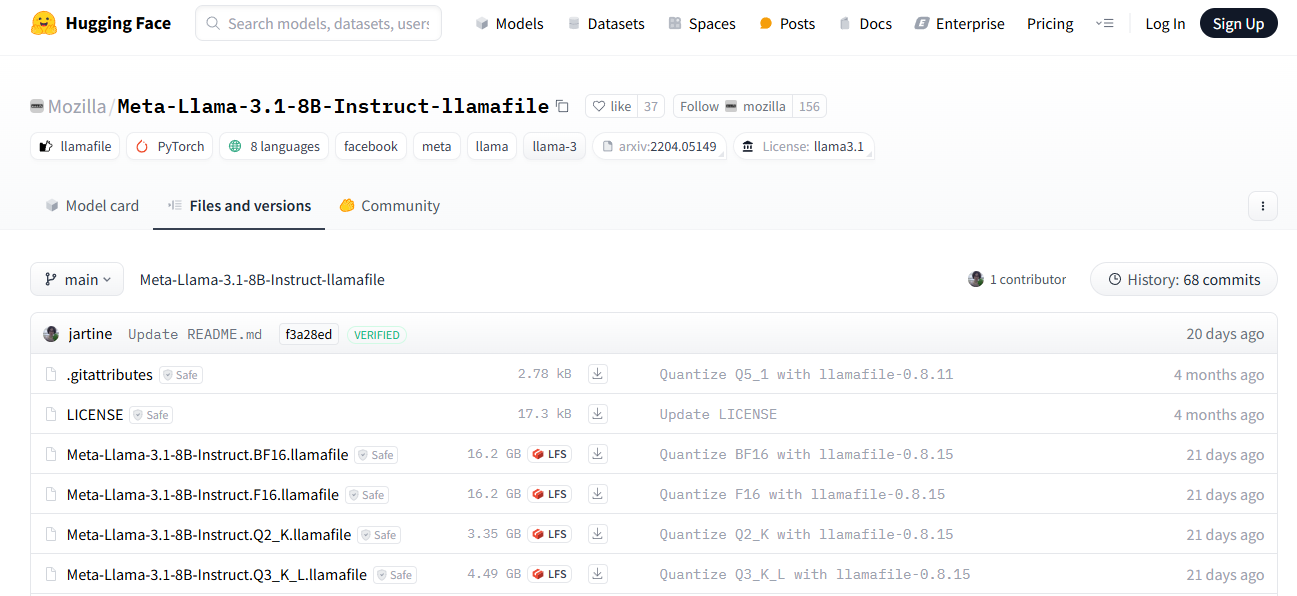
Llamafile is backed by Mozilla, which aims to support and make open-source AI accessible to everyone using fast CPU inference with no network access. It converts LLMs into multi-platform Executable Linkable Format (ELF). Allowing you to run LLMs with just a single executable file provides one of the best options for integrating AI into applications.
How Llamafile Works
It is designed to convert weights into several executable programs that require no installation to run on architectures such as:
- Windows
- MacOS
- Linux
- Intel
- ARM
- FreeBSD
- And more
Under the hood, Llamafile uses tinyBLAST to run on OSs like Windows without requiring an SDK.
Key Features
- Executable File: Unlike other LLM tools like LM Studio and Jan, Llamafile requires only one executable file to run LLMs.
- Use Existing Models: Llamafile supports using existing model tools like Ollama and LM Studio.
- Access or Make Models: You can access popular LLMs from OpenAI, Mistral, Groq, and more. It also supports creating models from scratch.
- Model File Conversion: You can convert the file format of many popular LLMs, for example, .gguf into .llamafile with a single command.```llamafile-convert mistral-7b.gguf``
Get Started With Llamafile
To install Llamafile, head to the Huggingface website, select Models from the navigation, and search for Llamafile. You can also install your preferred quantized version from the URL below.
Note: The larger the quantization number, the better the response. As the image above highlights, this article uses Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile, where Q6 represents the quantization number.
Step 1: Download Llamafile
Click any download button. From the link above get your preferred version. If you have the wget utility installed on your machine, you can download Llamafile using the command below.
wget https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/blob/main/Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
You should replace the URL with the version you like.
Step 2: Make Llamafile Executable
After downloading a particular version of Llamafile, you should make it executable using the following command by navigating to the file’s location.```chmod +x Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile```
Step 3: Run Llamafile
Prepend a period and forward slash ./ to the file name to launch Llamafile: ./Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
Benefits of Using Llamafile
Llamafile helps to democratize AI and ML by making LLMs easily reachable to consumer CPUs. Compared to other local LLM apps like Llama and cpp, Llamafile gives the fastest prompt processing experience and better performance on gaming computers. Since it performs faster, it is an excellent option for summarizing long text and large documents. It runs 100% offline and privately, so users do not share their data with any AI server or API.
Machine Learning communities like Hugging Face supports the Llamafile format, making it easy to search for Llamafile-related models. It also has a tremendous open-source community that develops and extends it further.
4. GPT4ALL: Your Local LLM Tool for Privacy
GPT4ALL is built upon privacy, security, and no internet-required principles. Users can install it on:
- Mac
- Windows
- Ubuntu
GPT4ALL has more monthly downloads, GitHub Stars, and active users other than Jan or LM Studio.
Key Features of GPT4ALL
GPT4All can run LLMs on major consumer hardware such as Mac M-Series chips, AMD and NVIDIA GPUs. The following are its key features:
- Privacy First: Keep private and sensitive chat information and prompts only on your machine.
- No Internet Required: It works completely offline.
- Models Exploration: This feature allows developers to browse and download different kinds of LLMs to experiment with. You can select about 1000 open-source language models from popular options like:
- LLama
- Mistral
- And more
- Local Documents: You can let your local LLM access your sensitive data with local documents like .pdf and .txt without data leaving your device and without a network.
- Customization Options: It provides several chatbot adjustment options, such as:
- Temperature
- Batch size
- Context length
- Others
- Enterprise Edition: GPT4ALL provides an enterprise package with security, support, and per-device licenses to bring local AI to businesses.
Get Started With GPT4All
To start using GPT4All to run LLMs locally, Download the required version for your operating system.
Benefits of Using GPT4ALL
Except Ollama, GPT4ALL has the most significant number of GitHub contributors and about 250000 monthly active users (according to https://www.nomic.ai/gpt4all) compared to its competitors. The app collects anonymous user data about usage analytics and chat sharing. But, users have the option to opt in or out. Using GPT4ALL, developers benefit from its large user base, GitHub, and Discord communities.
5. Ollama: The Local LLM Chatbot Creator
Using Ollama, you can easily create local chatbots without connecting to an API like OpenAI. Since everything runs locally, you do not need to pay for any subscription or API calls.
Key Features
- Model Customization: Ollama allows you to convert .gguf model files and run them with ollama run modelname.
- Model Library: Ollama has an extensive collection of models to try at ollama.com/library.
- Import Models: Ollama supports importing models from PyTorch.
- Community Integrations: Ollama integrates seamlessly into web and desktop applications like:
- Ollama-SwiftUI
- HTML UI
- Dify.ai
- And more
- Database Connection: Ollama supports several data platforms.
- Mobile Integration: A SwiftUI app like Enchanted brings Ollama to iOS, macOS, and visionOS. Maid is also a cross-platform Flutter app that interfaces with .ggufmodel files locally.
Get Started With Ollama
Benefits of Using Ollama
Ollama has over 200 contributors on GitHub with active updates. It has the largest contributors and is more extendable among the other open-source LLM tools discussed above.
6. LLaMa.cpp: The Local LLM Performance Booster
LLaMa.cpp is the underlying backend technology (inference engine) that powers local LLM tools like Ollama. It can also run in the cloud. Llama.cpp supports significant large language model inferences with minimal configuration and excellent local performance on various hardware.
Key Features
- Setup: It has a minimal setup. You install it with a single command. - Performance: It performs very well on various hardware locally and in the cloud.
- Supported Models: It supports popular and major LLMs like Mistral 7B, Mixtral MoE, DBRX, Falcon, and many others.
- Frontend AI Tools: LLaMa.cpp supports open-source LLM UI tools like MindWorkAI/AI-Studio (FSL-1.1-MIT), iohub/collama, etc.
Get Started With LLaMa.cpp
To run your first local large language model with llama.cpp, you should install it with:
brew install llama.cpp
Next, download the model you want to run from Hugging Face or any other source. For example, download the model below from Hugging Face and save it somewhere on your machine.Using your preferred command-line tool, like Terminal, cd into the location of the .gguf model file you just downloaded and run the following commands.
llama-cli --color
-m Mistral-7B-Instruct-v0.3.Q4_K_M.ggufb
-p "Write a short intro about SwiftUI"
7. PrivateGPT: An Offline LLM for Secure Data Analysis

PrivateGPT offers strong privacy features but requires a more technical setup, making it better suited for users with Python knowledge. For users concerned with privacy, PrivateGPT is a strong option. It’s well-suited for working with your own data and prioritizes keeping everything on your local machine.
Hardware Requirements
- Minimum: 16GB RAM, Intel i9 or equivalent processor.
- Recommended: GPU for larger models and faster performance.
Installing/Running the Tool
- Download the tool from its GitHub repository.
- To run the models, you must set up Python and install the required dependencies (such as PyTorch).
- Run the model from the command line with local interaction and querying options.
Working with Your Own Data
PrivateGPT excels in secure document analysis, supporting formats like PDFs, Word files, and CSVs. It processes large datasets by splitting them into smaller, manageable chunks, allowing for thorough document analysis.
Fine-Tuning Options
Fine-tuning is possible through external tools but requires advanced Python and machine-learning knowledge.
Example Use Cases
PrivateGPT is used in healthcare settings to transcribe patient interviews and generate medical summaries while keeping patient data local. Legal firms use it to analyze case files and provide insights without sharing confidential documents externally.
8. H2O.ai’s h2oGPT: A Local LLM for Enterprises

Ranked #5, h2oGPT is a powerful enterprise tool with a more complex installation process, making it the least accessible for beginners. H2oGPT is a high-performance tool targeted toward enterprise users that excels at large-scale document processing and chat-based interactions.
While it offers a web-based demo for leisure exploration, its local installation may require more technical knowledge and robust hardware.
Hardware Requirements
- Minimum: 16GB RAM for smaller models.
- Recommended: 64GB RAM and a high-end GPU for the best performance with larger models.
Installing/Running the Tool
- Download the desktop application or access the web demo to test its features.
- For local installations, Docker is recommended for managing dependencies.
GitHub Repository
Working with Your Own Data h2oGPT integrates with PrivateGPT to handle document queries, making it suitable for industries that process large datasets. It is designed to handle complex data but may experience slower performance without a GPU.
Fine-Tuning Options
H2O.ai’s ecosystem offers robust fine-tuning options, making it suitable for businesses that need customized LLMs for specific industry tasks.
Example Use Cases
Financial analysts use h2oGPT to process regulatory documents and extract actionable insights. Pharmaceutical companies rely on it to summarize and process clinical trial data for internal reports.
9. NextChat: A Local LLM for Advanced Users
NextChat, previously known as ChatGPT-Next-Web, is a chat application that allows us to use GPT-3, GPT-4, and Gemini Pro via an API key. It’s also available on the web UI, and we can even deploy our web instant using one click on Vercel.
Installation
We can download the installer from the GitHub repository. For Windows, select the .exe file.
Setting up the API Key
The NextChat application will run once we add a Google AI or OpenAI API key.
Generating the Response
On the main chat user interface page, click the robot button above the chat input and select the Gemini-pro model.
Using the NextChat Application
Similarly, we can use the OpenAI API key to access GPT-4 models, use them locally, and save on the monthly subscription fee.
Advanced Users
For more technically skilled users who want greater flexibility and control, the following tools offer powerful features and customization options:
LangChain
LangChain is a Python-based framework designed for building applications powered by LLMs. It allows developers to combine various models and APIs to create more complex workflows. LangChain supports local and cloud-based LLMs, making it a versatile choice for advanced applications.
Best For: Building end-to-end applications, embedding and retrieval tasks, and integrating LLMs into existing software.
MLC LLM
MLC LLM enables running advanced LLMs, such as Mistral, on consumer-grade hardware, including mobile devices. It’s designed for efficient model inference, optimizing performance for smaller devices without compromising model power.
Best For: Users who need to run models on constrained devices or across different operating systems (Windows, macOS, Linux, mobile).
Related Reading
- LLM Quantization
- LLM Distillation
- LLM vs SLM
- Best LLM for Data Analysis
- Rag vs LLM
- Foundation Model vs LLM
- ML vs LLM
- LLM vs Generative AI
- LLM vs NLP
Start Building GenAI Apps for Free Today with Our Managed Generative AI Tech Stack
Lamatic offers a managed generative AI tech stack. Our solution provides Managed GenAI Middleware, Custom GenAI API (GraphQL), Low-Code Agent Builder, Automated GenAI Workflow (CI/CD), GenOps (DevOps for GenAI), Edge deployment via Cloudflare workers, and Integrated Vector Database (Weaviate).
Accelerating AI Integration
Lamatic empowers teams to rapidly implement GenAI solutions without accruing tech debt. Our platform automates workflows and ensures production-grade deployment on the edge, enabling fast, efficient GenAI integration for products needing swift AI capabilities.
Start building GenAI apps for free today with our managed generative AI tech stack.





